A note on this post: I will be discussing the details to the solution of a problem that was solved by a co-worker of mine. See his blog, The Devel.
SQL has always been a bit of a mystery to me. To date, my most complicated queries have been fairly simple table joins. Recently I stumbled upon a problem that I would have traditionally solved by doing two or three separate dynamically generated queries executed from a programming language like Python. My mercifully patient co-workers explained the problem could be solved with one query that uses a few more advanced SQL concepts, including:
- a subquery
- GROUP BY
- HAVING
- ORDER BY
I can see versions of this problem (described below) coming up in other domains. I am going to walk through the solution in this post, from the most naive implementation up through a single query that solves the entire problem. Hopefully it will be a relatable guide to using some of SQL's interesting features. I am also posting a sample SQLite database that you can download and play with while working through the post. If you are not familiar with SQLite, it is a simple, server-less SQL database. It is very widely used and often embedded within other products (it might be running in your web browser). It is perfect for learning SQL because there is virtually no setup and it is almost impossible to break anything.
To get started, download the SQLite executable and the movies.db file. Once SQLite is installed, if you open a console and navigate to the location of your downloaded movies.db file and type:
sqlite3 movies.db
you will be at a SQL prompt ready to go.
Slightly Contrived Problem
You are in charge of assigning movies to movie reviewers. You have a list of movies, and a list of reviews tagged with the reviewer. When a reviewer asks for an assignment, you must assign him or her a movie that:
- They have not yet reviewed.
- Has only been reviewed by at most N other reviewers.
- Of the movies that fit criteria 1 and 2, each movie is just as likely to be assigned.
In summary, if we take N to be 1, you just want every movie to be reviewed by 1 reviewer, and you want every movie to have an equal chance of being reviewed.
For the purpose of this post, your data is stored in a database with the following two tables:
Movies Table
| id | name | length | year |
| 1 | The Shawshank Redemption | 2.5 | 1994 |
| 2 | The Dark Knight | 3 | 2008 |
| 3 | Fight Club | 2 | 1999 |
| 4 | Goodfellas | 2 | 1990 |
| 5 | Casablanca | 2 | 1942 |
Reviews Table
| id | reviewer | rating | movie |
| 1 | Grumpy | 0 | 4 |
| 2 | Happy | 5 | 2 |
| 3 | Sleepy | ? | 3 |
| 4 | Martin | 5 | 4 |
How I would solve this with brute-force, mediocre SQL
Sleepy wants his next assignment. The simplest solution to the problem is to:
- Do a select on the reviews table for all reviews by Sleepy.
- Do a select on the movies table, selecting all movies whose ids are not in the list created in step 1.
- Iterate through the list of movies from step 2, querying the review table for reviews for that movie. Then choose (at random) a movie whose number of reviews is < N.
Lets work through this at the SQLite prompt:
sqlite> SELECT * FROM reviews WHERE reviewer='Sleepy';
3|Sleepy|?|3
Then generate a SQL query on the movies table to grab all the movies Sleepy has not yet reviewed.
sqlite> SELECT * FROM movies WHERE id NOT IN (3);
1|The Shawshank Redemption|2.5 hours|1994
2|The Dark Knight|3 hours|2008
4|Goodfellas|2 hours|1990
5|Casablanca|2 hours|1942
Finally, iterate through each movie returned in the previous query, constructing a query to count the number of reviews for that movie.
sqlite> SELECT COUNT(*) FROM reviews WHERE movie = 1;
0
sqlite> SELECT COUNT(*) FROM reviews WHERE movie = 2;
1
sqlite> SELECT COUNT(*) FROM reviews WHERE movie = 4;
2
sqlite> SELECT COUNT(*) FROM reviews WHERE movie = 5;
0
Shawshank had no reviews, The Dark Knight had 1 review, Goodfellas had 2 reviews, and Casablanca had no reviews. If N was equal to 1, randomly choose between Shawshank and Casablanca, assigning one of them to Sleepy. All done!
How can this be done better?
The first step in improving this process is to introduce a subquery. We can essentially do our first two queries above in one call to the database like this:
sqlite> SELECT id, name FROM movies WHERE id NOT IN (SELECT movie FROM reviews WHERE reviewer='Sleepy');
1|The Shawshank Redemption
2|The Dark Knight
4|Goodfellas
5|Casablanca
We now know the names of the movies that Sleepy has not reviewed. We could now just do step 3 above, iterating through each movie to find out how many reviews we have for each one.
Brief Aside
One thing I found confusing when going from trivial SQL queries to more complex problems was that by doing a SELECT from more than one table using a WHERE clause, you are doing an implicit inner join. There are quite a few different types of joins that you can actually perform. I have found the following two links helpful: Jeff Atwood explains SQL joins using Venn Diagrams and Wikipedia takes a crack at SQL join types. So for example, if we wanted to do an inner join on our two tables, one way would be with the following query:
sqlite> SELECT * FROM movies, reviews WHERE movies.id = reviews.movie;
4|Goodfellas|2 hours|1990|1|Grumpy|0|4
2|The Dark Knight|3 hours|2008|2|Happy|5|2
3|Fight Club|2 hours|1999|3|Sleepy|?|3
4|Goodfellas|2 hours|1990|4|Martin|5|4
Here we get a row for each movie review. If there is no review, the movie is not showing up at all. This is because it did an implicit inner join. Other types of joins would produce different results. The same query using the more explicit syntax:
SELECT * FROM movies INNER JOIN reviews ON (movies.id = reviews.movie);
4|Goodfellas|2 hours|1990|1|Grumpy|0|4
2|The Dark Knight|3 hours|2008|2|Happy|5|2
3|Fight Club|2 hours|1999|3|Sleepy|?|3
4|Goodfellas|2 hours|1990|4|Martin|5|4
For clarity's sake, I will use the more explicit syntax from here on out.
But we can do better
Let's join these two tables.
So if we join these two tables on the movie id, and select only the fields we actually care about, we could write the following query:
sqlite> SELECT movies.name, reviews.reviewer FROM movies INNER JOIN reviews ON (movies.id = reviews.movie);
Goodfellas|Grumpy
The Dark Knight|Happy
Fight Club|Sleepy
Goodfellas|Martin
The above query might also be written like this
SELECT M.name, R.reviewer FROM movies M INNER JOIN reviews R ON (M.id = R.movie);
Just look this over for a second and it should become clear that the M and R following the table names are aliases. Everywhere else in the query that alias is used to refer to its associated table name. You will probably see this used in the SQL wild.
So we have joined our two tables and grabbed only the information we really cared about. If we add back our subquery, we get this:
sqlite> SELECT M.name, R.reviewer FROM movies M INNER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy');
Goodfellas|Grumpy
The Dark Knight|Happy
Goodfellas|Martin
We now have one row for each movie not reviewed by Sleepy. We could almost solve this problem now without hitting the database again except for the fact that we don't have any information about movies that have no reviews. From here we could do a SELECT * on the movies table, and we would have enough information to programatically figure out what movie to assign Sleepy.
But we don't have to hit the database twice
We can fix this by changing our join type. If you refer to the links above on join types, you will see there is a "left outer join". This will do a join on the tables on the value specified, but even if there is no matching table on the right side of the join, we will still get a row of data from the left table. Lets try it
sqlite> SELECT M.name, R.reviewer FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') ;
The Shawshank Redemption|
The Dark Knight|Happy
Goodfellas|Grumpy
Goodfellas|Martin
Casablanca|
The results are exactly the same as above except that we have a row for Shawshank and Casablanca with no corresponding reviewer. We now have enough information to programatically find a movie for Sleepy to review.
Can we make the database do that too?
Yes
We can use COUNT, GROUP BY, HAVING, ORDER BY, and a database dependent RANDOM() function to have the database return just the name of a movie Sleepy should review.
Lets throw COUNT and GROUP BY in there.
sqlite> SELECT M.name, R.reviewer FROM movies M INNER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy');
SELECT M.name, COUNT(R.reviewer) FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') GROUP BY M.name;
Casablanca|0
Goodfellas|2
The Dark Knight|1
The Shawshank Redemption|0
GROUP BY works by rolling up all identical values of fields after your SELECT statement, aside from variables inside aggregate functions (which COUNT is), into a single row. So instead of getting one row per movie review as before, we are getting one row per unique movie, and the corresponding reviewer variable has been converted into a count of the number of reviewers associated with each row that was grouped.
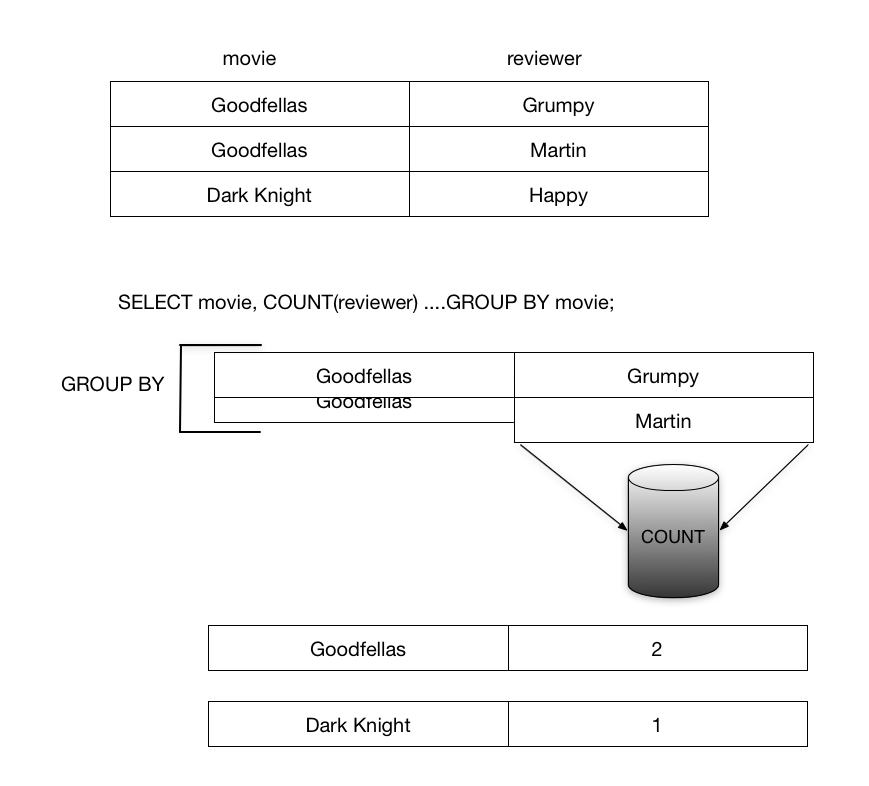
GROUP BY can be confusing, in particular because depending on which fields you put after your SELECT statement and your GROUP BY clause, the results might not make any sense. The general rule is that any field coming after your SELECT statement that is not in an aggregate function (a function that takes many values and outputs one, like COUNT and SUM) must be in your GROUP BY clause as well, otherwise it either will not work, or the meaning of the query is not well defined. GROUP BY really could be its own post (and I am sure it is elsewhere).
But we still don't have the database answering this question for us. Lets move that COUNT variable into a HAVING clause.
sqlite> SELECT M.name FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') GROUP BY M.name HAVING COUNT(R.reviewer) < 1;
Casablanca
The Shawshank Redemption
Here, moving the COUNT function into the HAVING portion of our query, we are able to look at our groups before passing it up to the rest of the query. We are saying: "only create this group, if the corresponding reviewer count is less than one". As you can see, we now just have a list of movie names that no one, including Sleepy, has reviewed. It appears that in some databases you cannot refer to a field in your HAVING clause if it was not listed after your SELECT statement, so you might have to do the following (which gives me the chance to introduce the aliasing of fields in your SELECT statement using AS)
sqlite> SELECT M.name, count(R.reviewer) AS C FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') GROUP BY M.name HAVING C < 1;
Here we put the COUNT function back into the select statement, alias it as C, and then refer to that in our HAVING clause. The alias here is optional, I just did it because it can be done, you can alias any field after your SELECT statement, not just functions. It is also important to note that the HAVING portion works on things other than functions. Depending on what you are trying to accomplish it may become confusing as to whether something belongs in a HAVING clause or a WHERE clause. It comes down to where you want to perform the check (either as each row is examined, or as each group is created). I found the following link helpful:
For this problem though, we definitely need the check to be in the HAVING clause, because the value of the COUNT aggregate function will not yet be defined in the WHERE clause. At the point in time the WHERE clause is being executed the database is still determining which rows are actually in our results and correspondingly, which rows the GROUP BY will be performed on. The HAVING clause allows us to perform checks on the grouped rows.
Make the database choose one row at random
So we have a query returning a list of movies that Sleepy can review. But he is not a workaholic- he only wants one job, not two. Additionally, he needs to have an equal chance of being assigned either film. We solve the too many jobs problem by sticking a LIMIT on the end of the query:
sqlite> SELECT M.name, count(R.reviewer) AS C FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') GROUP BY M.name HAVING C < 1 LIMIT 1;
Casablanca|0
This tells the database to only return 1 row from the result set. Unfortunately, every time we run this it will return the same row. We need to get it to randomly pick one of them for us. We can do this by using ORDER BY and then a database specific function. ORDER BY tells the database to return the results ordered by one of the fields. For example, we could ask it to ORDER BY movie.name, and it would always return them in alphabetical order. By using a special function (called RANDOM in SQLite and Postgres), we can have the database assign a random value to each row and then order by that value. So to bring it all together:
sqlite> SELECT M.name, count(R.reviewer) AS C FROM movies M LEFT OUTER JOIN reviews R ON (M.id = R.movie) WHERE M.id NOT IN (SELECT movie FROM reviews WHERE reviews.reviewer = 'Sleepy') GROUP BY M.name HAVING C < 1 ORDER BY RANDOM() LIMIT 1;
The Shawshank Redemption|0
If you run this multiple times the result will change. That's it! See this link for database specific random functions:
http://www.petefreitag.com/item/466.cfm
Any corrections or alternative solutions?
Thanks for reading, please leave any comments or corrections.